Managing large changeable, or rapidly changing dimensions
In the context of a very large HV-type dimension, or in which changes occur very quickly, the implementation of a type-2 change would not be feasible.
The solution is to implement the mini-dimension concept, which consists in isolating the attributes in a dimension table that are changing too quickly for them to be compiled in a new dimension. This dimension differs in the sense that each row corresponds to a profile. Each profile corresponds to a combination of values or ranges of values for each of the attributes in order to:
- reduce the number of rows in the dimension
- correspond to a business use
Example
Let’s take the example of a health insurance company. To enable the monitoring of insurance policy sales, the dimensional schema presented in the schema below has been proposed.
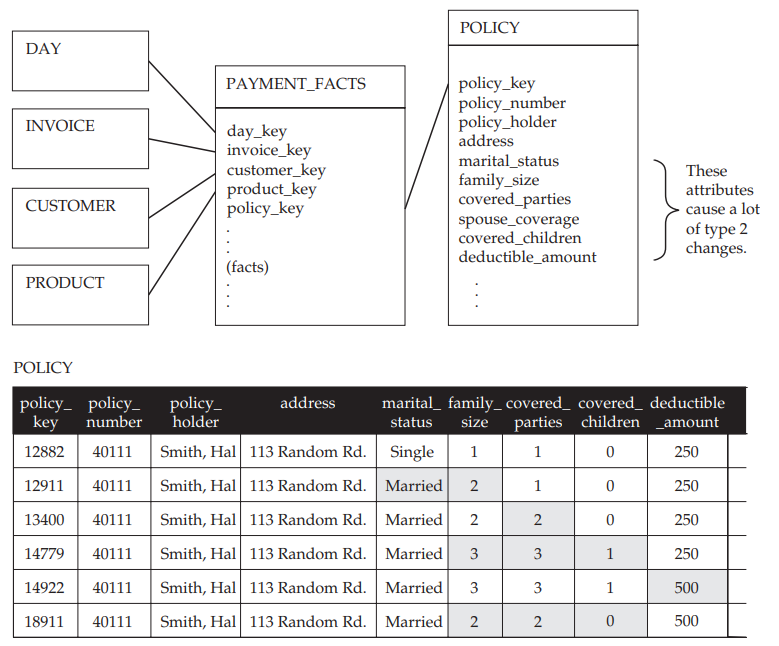
We can see that the POLICY dimension is an HV-type dimension because for each change in the marital_status, family_size, covered_parties, covered_children and deductible_amount attributes, a new row has been added to retain the information about the insurance policy taken out and the customer’s coverage. In the table above, it is clear that this concerns the same insurance policy because the business key (BK) corresponding to the policy_number attribute always retains the same value 40111. The policy_key attribute is a surrogate key, which in this case enables us to manage changes in the insurance policy.
To manage changes in the POLICY dimension, we shall divide it into two dimensions: a POLICY dimension exclusively containing the permanent information about the policy (here, the business key and the policyholder), and a POLICY_COVERAGE dimension containing information about the policyholder’s coverage (see figure below).
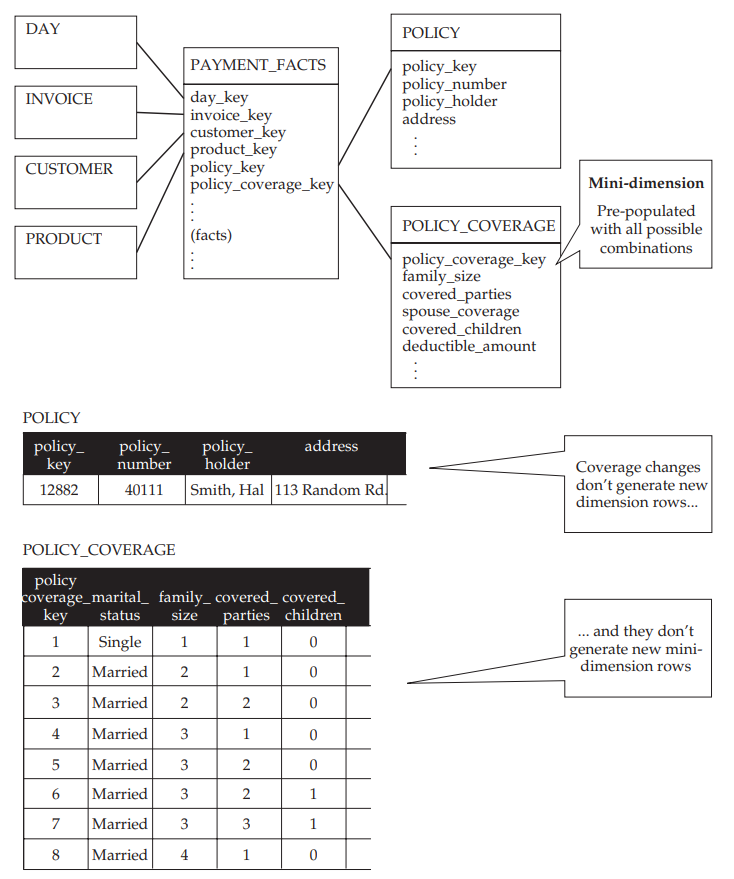
The POLICY_COVERAGE dimension is populated (i.e. filled with rows) once and for all by filling it with all possible combinations of attribute values to describe a policyholder’s coverage. However, exercise caution with regard to the resulting cardinality! Whilst no problems arise for attributes with only a limited possible number of discrete values (family_size, covered_parties, covered_children), attributes such as deductible_amount could cause the number of profiles to increase uncontrollably. That is why, for this type of continuous value attribute, we must transform it into a value range, e.g. 0-200, 200-500 or 500+.
In the fact table, we will therefore need to associate a policy reference and a reference to the corresponding coverage with each insurance policy sale. The size of the POLICY_COVERAGE dimension is now controlled, and the POLICY dimension no longer changes to type 2. However, a problem arises: how can we find out about the current coverage provided by a policy? Indeed, the fact table only containes the information applicable on the subscription date. For this purpose, we shall simply add a reference key in POLICY to the current POLICY_COVERAGE value (see the figure below).
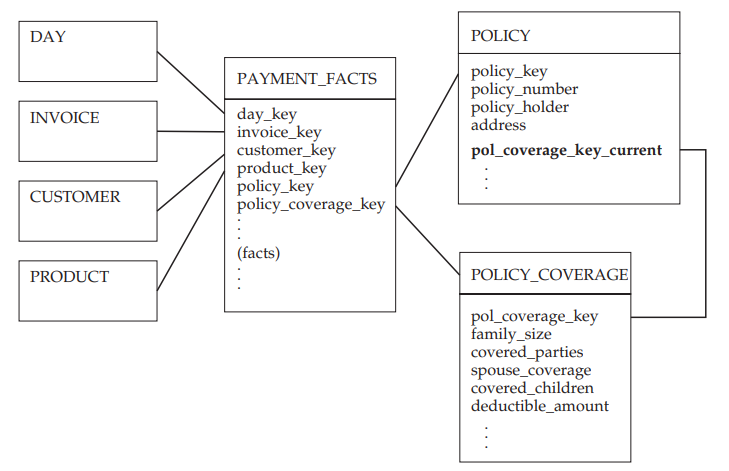
In this way, the POLICY_COVERAGE dimension becomes an outrigger dimension, in addition to being a mini-dimension.
Reading Mini-dimension: Star Schema. Christopher Adamson. pages 123-126
Reading Mini-dimension: Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 166