Avant de lire ce contenu, vous devez obligatoirement maîtriser les notions de base en modélisation dimensionnelle :
- Modélisation dimensionnelle - Introduction
Gestion des cardinalités multiples : la table passerelle
Diaporama Table passerelle
Prenons l’exemple d’une table de faits ORDER_FACTS contenant les commandes d’un produit PRODUCT passées à une date donné DAY, par un client donné CUSTOMER mais suivies par potentiellement plusieurs commerciaux SALESREP.
Comment modéliser le fait qu’une table de faits ait une relation N-M (plusieurs à plusieurs) avec une dimension ?
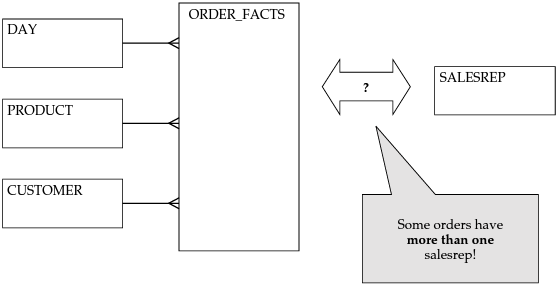
Source : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema. Laurence Corr and Jim Stagnitto. DecisionOne Press, 2011
La solution consiste à introduire une table, appelée table passerelle, pour gérer la multiplicité des cardinalités. Cette table passerelle permet de gérer différentes situations :
- La relation N-M se situe entre la table de faits et une dimension (dimension multivaluée)
- La relation N-M se situe entre deux dimensions (attribut multivalué)
Considérons plus en détail ces deux situations.
Dimension multivaluée (Relation N-M entre une table de faits et une dimension)
Poursuivons notre exemple où une commande (ligne dans ORDER_FACTS) est rattachée à plusieurs commerciaux au sein de l’entreprise. Nous allons résoudre le problème au moyen d’une table passerelle SALES_GROUP qui va permettre de définir des équipes de commerciaux. La table de faits ORDER_FACTS n’aura qu’un seul groupe à référencer, tandis que chaque groupe pourra être associé à plusieurs commerciaux (figure ci-dessous).
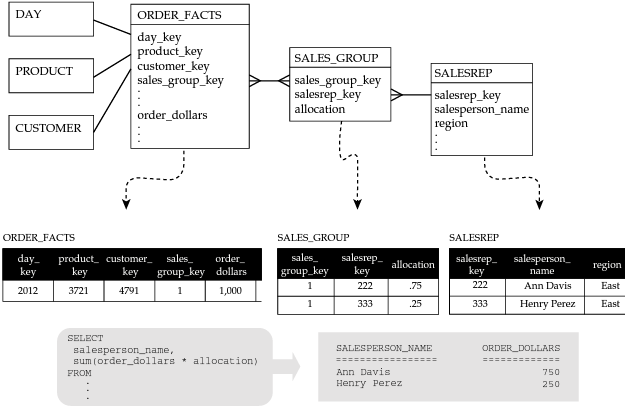
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010
On remarquera dans la table SALES_GROUP une clef d’allocation allocation permettant d’attribuer une part de la commande (quelle que soit la mesure choisie) entre les différents commerciaux.
Lecture Dimension multivaluée : Star Schema. Christopher Adamson. pages 195, 198-200
Lecture Dimension multivaluée : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 265-266
Lecture Table passerelle pour la gestion des cardinalités multiples : Star Schema. Christopher Adamson. pages 199-204
Lecture Table passerelle pour la gestion des cardinalités multiple : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 268-276
Attribut multivalué (Relation N-M entre une dimension et une table déportée).
Considérons un autre exemple où un client CUSTOMER est associé à un type d’industrie INDUSTRY. Un problème se pose lorsqu’il peut y avoir plusieurs types d’industries permettant de qualifier le client.
Nous résolvons le problème ici en plaçant la table passerelle entre les dimensions CUSTOMER et INDUSTRY (figure ci-dessous).
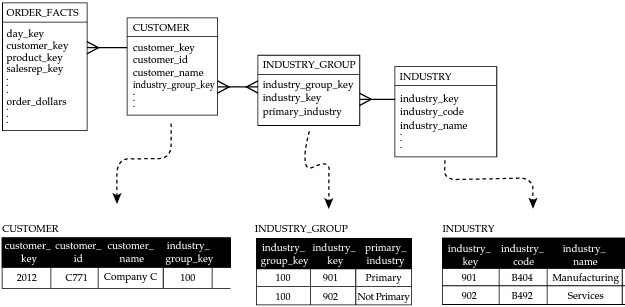
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010
Lecture Attribut multivalué : Star Schema. Christopher Adamson. pages 195, 207-210
Gestion des hiérarchies à profondeur variable : la table passerelle
Prenons l’exemple d’une société qui fait ses produits uniquement en B2B (c’est-à-dire à une autre société). Cependant, certains de ses clients sont des entreprises qui font partie d’un groupe plus global et ainsi de suite.
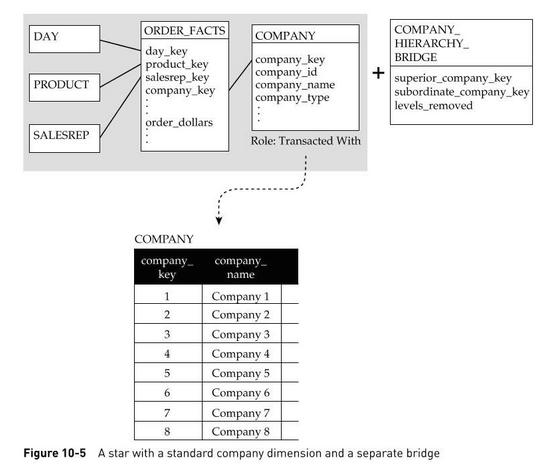
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010
Il n’est cependant pas possible de savoir, pour chaque client, le niveau de hiérarchie auquel il faut s’attendre. C’est pourquoi nous devons utiliser ici un patron de conception nommé hiérarchie à profondeur variable.
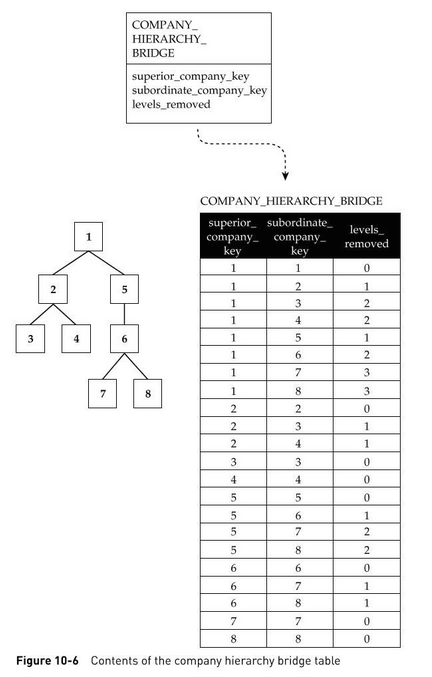
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010
Lecture Hiérarchie récursive / Hiérarchie à profondeur variable : Star Schema. Christopher Adamson. pages 219-221
Lecture Hiérarchie récursive / Hiérarchie à profondeur variable : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 76, 175
Lecture Table passerelle pour hiérarchie à profondeur variable : Star Schema. Christopher Adamson. pages 227-235
Lecture Table passerelle pour hiérarchie à profondeur variable : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 176-178
Dimension à évolution lente
Diaporama Dimension à évolution lente
Les dimensions sont utilisées comme axe d’analyse pour explorer nos données. Une dimension peut être vue comme un catalogue qui fait l’inventaire “d’objets” : la liste des clients, des produits, des périodes d’observation. Ces catalogues de données ne sont pas immuables : les données peuvent changer. Ces changements peuvent être de nature différentes : la correction d’une erreur, un changement occasionnel sur une petite partie des données, des changements rapides ou concernant un plus grand volume de données. Dans cette section, nous allons nous intéresser aux changements peu fréquents qui sont gérés par les dimensions à évolution lente.
Il existe 3 types d’évolutions lentes possibles qui correspondent à des besoins d’historisation différents :
- Évolution de type 1 - Écrasement de la valeur (pas d’historisation)
- Évolution de type 2 - Sauvegarde de chaque modification
- Évolution de type 3 - Sauvegarde de la dernière modification
Prenons l’exemple d’une table de faits Order_facts dont l’objectif est de rassembler les informations concernant des commandes.
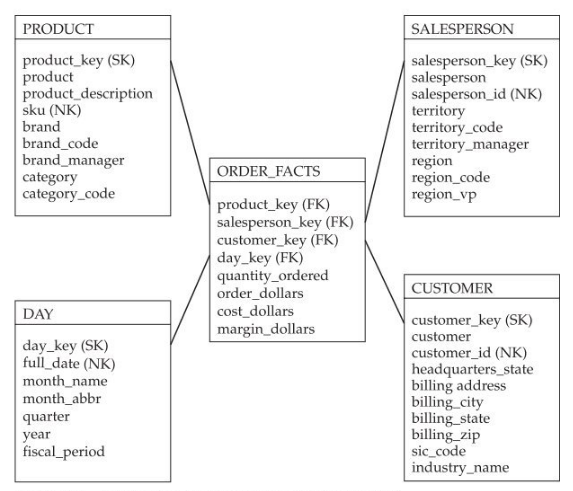
Source du schéma : Adamson, Christopher. Star Schema. Osborne/McGraw-Hill, 2010, page 30
Lecture Dimension à évolution lente : Star Schema. Christopher Adamson. pages 44-46, 171
Lecture Dimension à évolution lente : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 84-93
Évolution de type 1 : Écrasement de la valeur
Considérons le client Johnson Sue (1499). Sa date de naissance est erronée dans le système. La date de naissance est généralement de type FV (Fixed Value) c’est-à-dire qu’elle n’est pas censée changer. Dans ce contexte, nous avons besoin de procéder à une correction de la valeur sans conservation de l’historique (voir figure ci-dessous). L’ancienne valeur est donc écrasée. On appliquera cette même approche aux attributs de type CV (Current Value) dont on n’a pas besoin de conserver l’historique.
On constate enfin que cette modification n’a aucun impact sur la table de faits. Cependant, si des agrégats avaient été précalculés (sur tous les clients d’une tranche d’âge par exemple), il est nécessaire de les reconstruire.
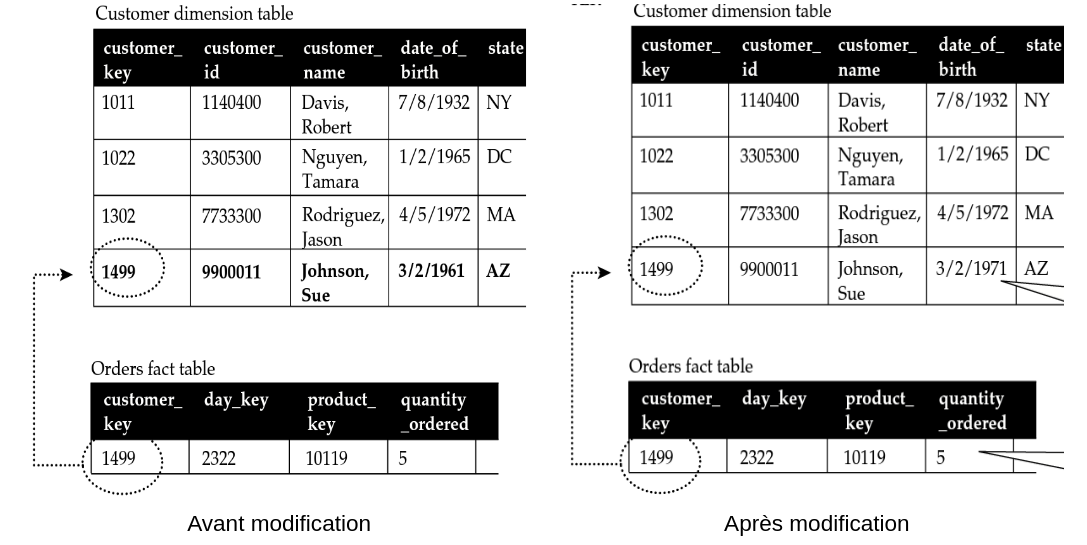
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010, page 47
Lecture Évolution de type 1 (CV) : Star Schema. Christopher Adamson. pages 46-48, 171
Lecture Évolution de type 1 (CV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 84-88
Évolution de type 2 : Ajout d’une nouvelle ligne à chaque modification
Considérons toujours le même client Johnson Sue (ID 1499) qui, cette fois-ci, déménage de l’Arizona AZ à la Californie CA. Après discussion avec les experts métiers, il a été jugé important de garder l’historique complet des changements d’adresse des clients lorsqu’ils changent d’état. En effet, certaines requêtes sont spécifiques aux performances des magasins selon les différentes zones géographiques. Il est ainsi nécessaire, pour une période donnée, d’identifier tous les clients qui habitaient dans un état donné.
L’attribut state est donc de type HV (Historic Value). Pour gérer les changements de cet attribut, nous allons créer une nouvelle ligne dans la dimension :
- Avec une nouvelle valeur de clef artificielle : le client
Johnson Sueaura donc 2 clefs associées1499et2507qui correspondront chacun à une adresse différente. - Pour faire le lien entre ces 2 lignes, nous utilisons la clef métier (Business Key
BK)customer_idqui conserve sa valeur9900011.
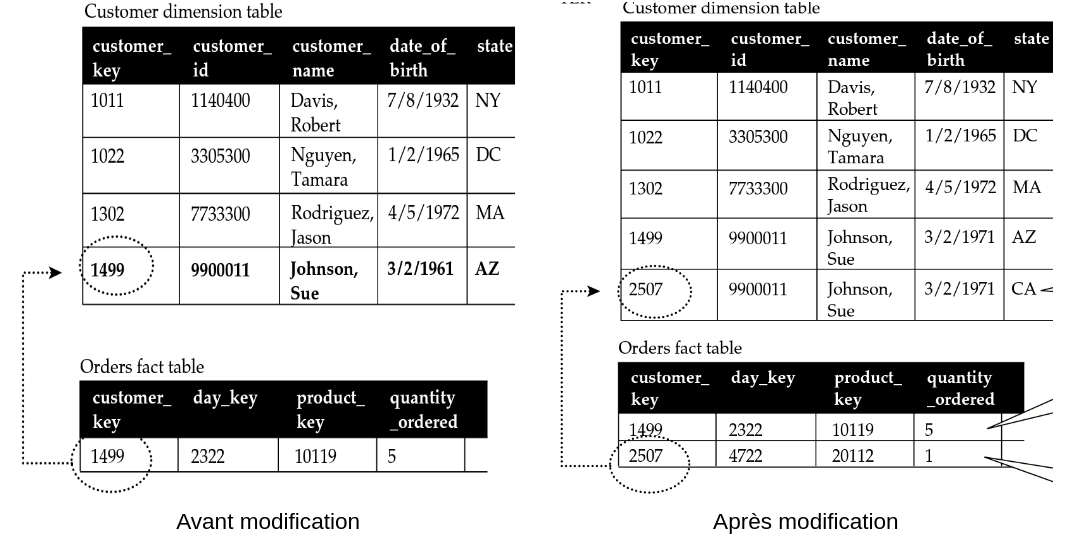
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010, page 49
Dans ce type d’évolution, il n’est pas nécessaire de reconstruire les agrégats dans la table de faits : rien ne change pour les données passées. Par contre, désormais, toutes les commandes effectuées par Johnson Sue le client se feront avec son nouvel identifiant 2507.
Attention toutefois à ce type d’évolution. Chaque modification induit l’ajout d’une nouvelle ligne. Il est donc nécessaire de faire attention à la taille de la dimension et à sa croissance. Si la dimension devient trop grande, il faut adopter la solution concernant les grandes dimensions changeantes ou à évolution rapide (voir ci-dessous).
Enfin, c’est l’occasion de revenir sur la notion de clef artificielle. Nous avons vu précédemment qu’elles étaient utiles pour nous isoler du système opérationnel, nous nous rendons compte ici qu’elles sont indispensables pour la gestion des évolutions de type 2.
Lecture Évolution de type 2 (HV) : Star Schema. Christopher Adamson. pages 48-51
Lecture Évolution de type 2 (HV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 86-92
Évolution de type 3 : Ajout d’une colonne pour sauvegarder la dernière modification
Considérons une entreprise qui a segmenté le territoire du pays sur lequel elle opère en 2 régions : Est et Ouest. Une croissance de l’entreprise et une restructuration ont conduit à redécouper le territoire de manière plus fine (Nord-Est, Sud-Est …).
Dans la figure ci-dessous, on se rend compte que certains clients ont désormais changé de zone d’affectation. Ce type de changement sera rare dans l’histoire de l’entreprise et les experts métiers veulent uniquement pouvoir observer l’impact de ce découpage administratif. Il leur est donc nécessaire de pouvoir faire des requêtes en fonction de l’ancien ou du nouveau découpage. L’attribut concerné, region, est donc de type PV (Previous Value), c’est-à-dire qu’on ne veut conserver que la valeur précédente.
La mise en œuvre de la solution d’évolution de type 3 consiste en la création de 2 attributs region, un pour la valeur courante region_current et l’autre pour la dernière valeur à historiser region_previous. Il faut faire attention à ne pas abuser de ce type d’évolution, car cela va faire grandir très rapidement le nombre de colonnes de la dimension.
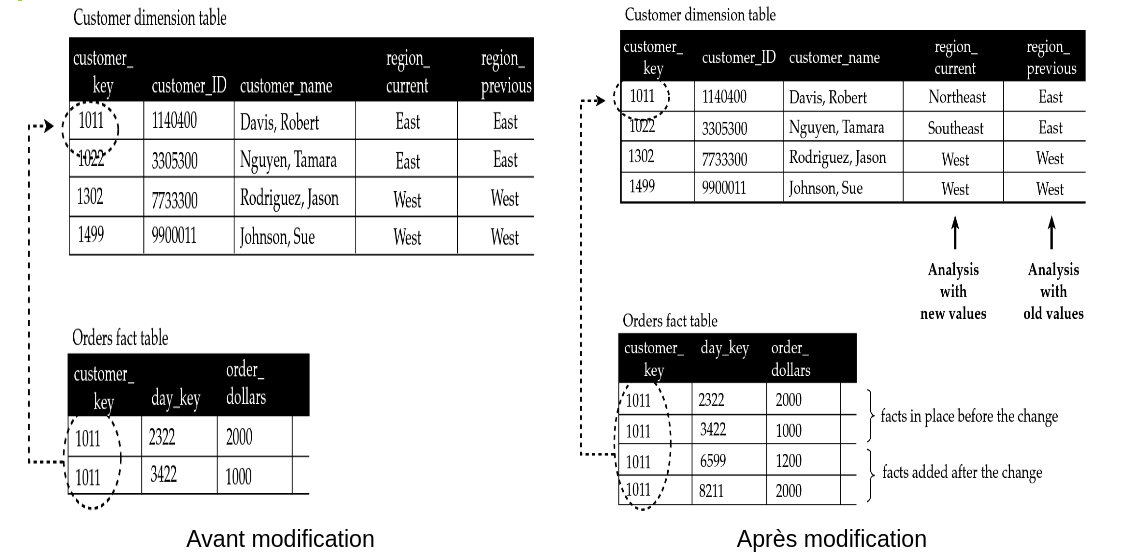
Source du schéma : Star Schema. Adamson, Christopher. Osborne/McGraw-Hill, 2010, page 183
Au niveau de la table de faits, il sera nécessaire de recalculer tous les agrégats (en fonction du point de vue actuel ou passé que l’on souhaite observer).
Lecture Évolution de type 3 (PV) : Star Schema. Christopher Adamson. pages 180-186
Lecture Évolution de type 3 (PV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 88, 188-189
Évolution hybrides
Il existe certaines situations où il est nécessaire de combiner les solutions précédentes. Nous ne les détaillerons pas ici mais si vous êtes intéressés vous pouvez utiliser les références ci-dessous.
Lecture Évolution hybrides (CV/HV) : Star Schema. Christopher Adamson. pages 186-192
Lecture Évolution hybrides (CV/HV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 88, 186-188
Gestion des grandes dimensions changeantes ou à évolution rapide : la mini-dimension
Diaporama Grande dimension changeante ou à évolution rapide
Dans le contexte d’une dimension de type HV de très grande taille ou dont les évolution sont très rapides il n’est pas envisageable de mettre en oeuvre une évolution de type 2.
La solution est de mettre en oeuvre la concept de mini-dimension. Il s’agit d’isoler de la table de dimensions les attributs dont l’évolution est trop rapide pour les assembler dans une nouvelle dimension. Cette dimension sera particulière dans le sens où chaque ligne correspondra à un profil. Chaque profil correspond à une combinaison de valeurs ou de plages de valeurs pour chacun des attributs de façon à :
- réduire le nombre de lignes dans la dimension
- correspondre à un usage métier
Prenons l’exemple d’une compagnie d’assurance santé. Afin d’avoir un suivi des ventes de polices d’assurance, le schéma dimensionnel présenté dans le schéma ci-dessous a été proposé.
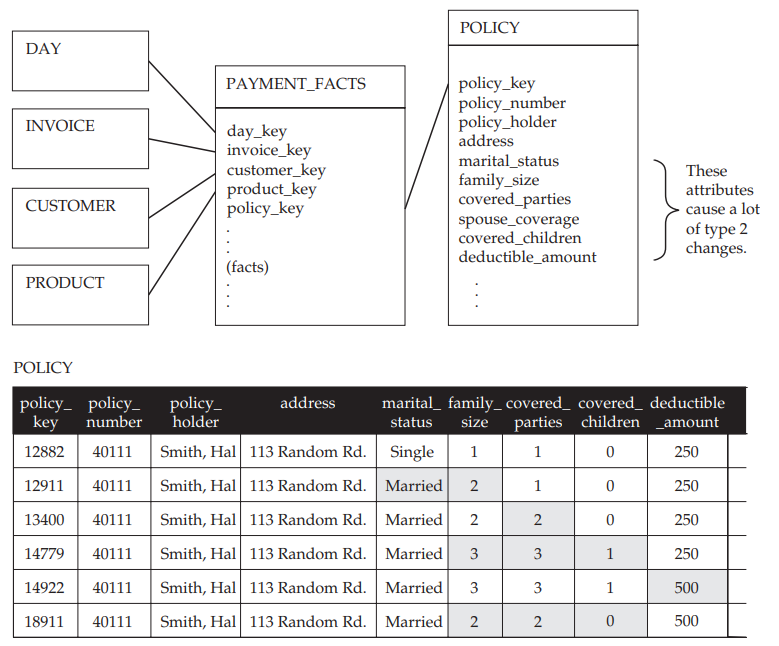
On constate que la dimension POLICY est une dimension de type HV car à chaque modification des attributs marital_status, family_size, covered_parties, covered_children, deductible_amount on a ajouté une nouvelle ligne pour conserver les informations de la police d’assurance souscrite et de la couverture du client. Dans le tableau ci-dessus on comprend qu’il s’agit de la même police d’assurance car la clef métier (Business Key BK) correspondant à l’attribut policy_number reste toujours à la même valeur 40111. L’attribut policy_key, quant à lui, est une clef artificielle nous permettant ici de gérer l’évolution de la police d’assurance.
Afin de gérer l’évolution de la dimension POLICY, nous allons la diviser en deux dimensions : une dimension POLICYqui ne contiendra plus que les informations permanentes concernant la police (ici la clef métier et l’assuré) et une dimension POLICY_COVERAGE qui contiendra les informations concernant la couverture de l’assuré (voir figure ci-dessous).
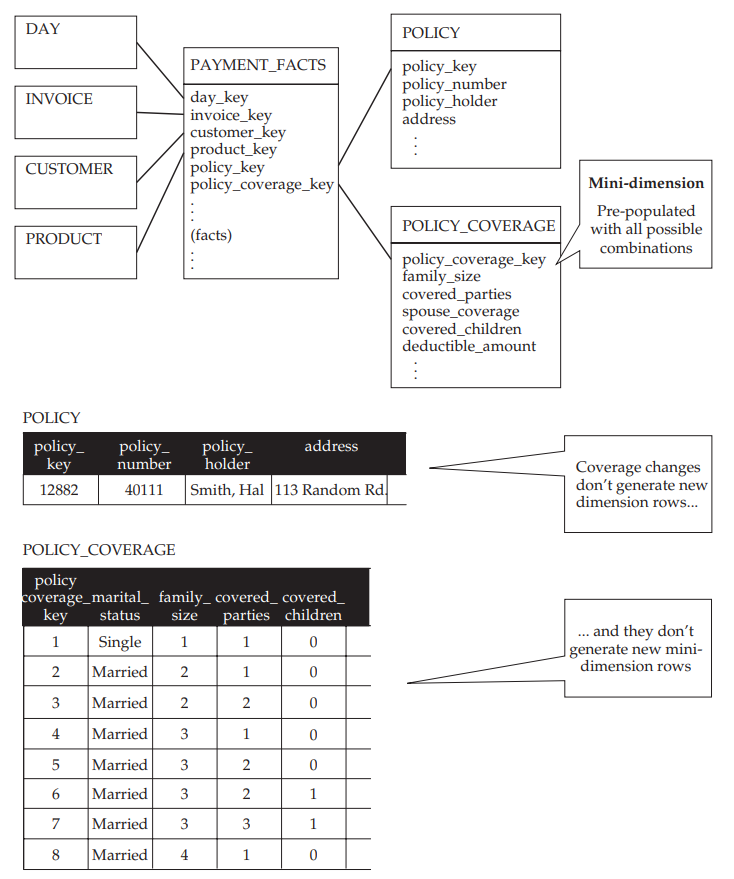
La dimension POLICY_COVERAGE est peuplée (c’est-à-dire remplie de lignes) une fois pour toutes en la remplissant de toutes les combinaisons possibles des valeurs d’attributs pour décrire la couverture d’un assuré. Attention toutefois à la cardinalité résultante ! Si les attributs ayant peu de valeurs discrètes possibles, il n’y a pas de problèmes (family_size, covered_parties, covered_children), les attributs comme deductible_amount pourraient faire exploser le nombre de profils. C’est pourquoi, pour ce type d’attributs à valeurs continues, nous allons le transformer en une plage de valeurs : 0-200, 200-500 et 500+ par exemple.
Au niveau de la table de faits, nous aurons ainsi à associer à chaque vente de police d’assurance une référence à la police et une référence à la couverture correspondante. La taille de la dimension POLICY_COVERAGE est désormais contrôlée et la dimension POLICE n’évolue plus en type 2. Un problème se pose toutefois : comment connaître la couverture actuelle offerte par une police ? En effet, dans la table de faits, nous n’avons l’information que pour le jour de la souscription. Pour cela, nous allons simplement ajouter une clef référentielle dans POLICY vers la valeur actuelle de POLICY_COVERAGE (voir figure ci-dessous).
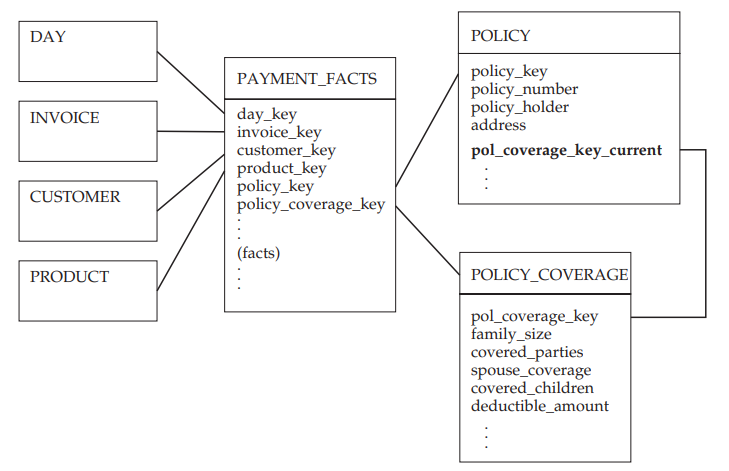
En faisant cela, la dimension POLICY_COVERAGE devient une dimension déportée, en plus d’être une mini-dimension.
Lecture Mini-dimension : Star Schema. Christopher Adamson. pages 123-126
Lecture Mini-dimension : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 166
Dimension déportée
Diaporama Dimension déportée
Une dimension déportée est une dimension qui est pointée par une autre dimension. L’utilisation d’une dimension déportée permet d’analyser deux dimensions sans passer par une table de faits. Elle doit se faire pour répondre à des usages spécifiques :
- Faire le lien entre une dimension et l’état courant d’un profil associé contenu dans une mini-dimension
- Séparer une partie des attributs d’une dimension volumineuse
Lien entre une dimension et l’état courant de sa mini-dimension
Le schéma ci-dessus dans la section mini-dimension aborde la situation dans laquelle une mini-dimension devient la dimension déportée de la dimension qu’elle allège de façon à maintenir l’information de la valeur courante du profil contenu dans la mini-dimension.
Lecture Dimension déportée pour gérer une mini-dimension : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. page 169
Séparer une partie des attributs d’une dimension volumineuse
 Prenons l’exemple d’une dimension
Prenons l’exemple d’une dimension SALESREP (figure ci-contre) contenant les informations aux sujets des vendeurs d’une entreprise. Cette dimension contient un grand nombre d’attributs. On peut remarquer deux ensembles d’attributs liés à des localisations (reporting_location et work_location) et des dates (hire et review).
Un sujet de préoccupation est ici le maintien de la cohérence des informations contenues dans cette dimension. Cette préoccupation est d’autant plus importante qu’il est possible que les informations concernant certaines localisations et dates soient gérées par ailleurs par d’autres processus ETL. Nous nous retrouvons alors dans un contexte où de multiples processus ETL ciblent la même dimension.
Dans ce contexte, il peut être judicieux d’éliminer les groupes d’attributs qui se répéte pour les stocker dans des dimensions déportées, ici DAYet LOCATION(figure ci-dessous).
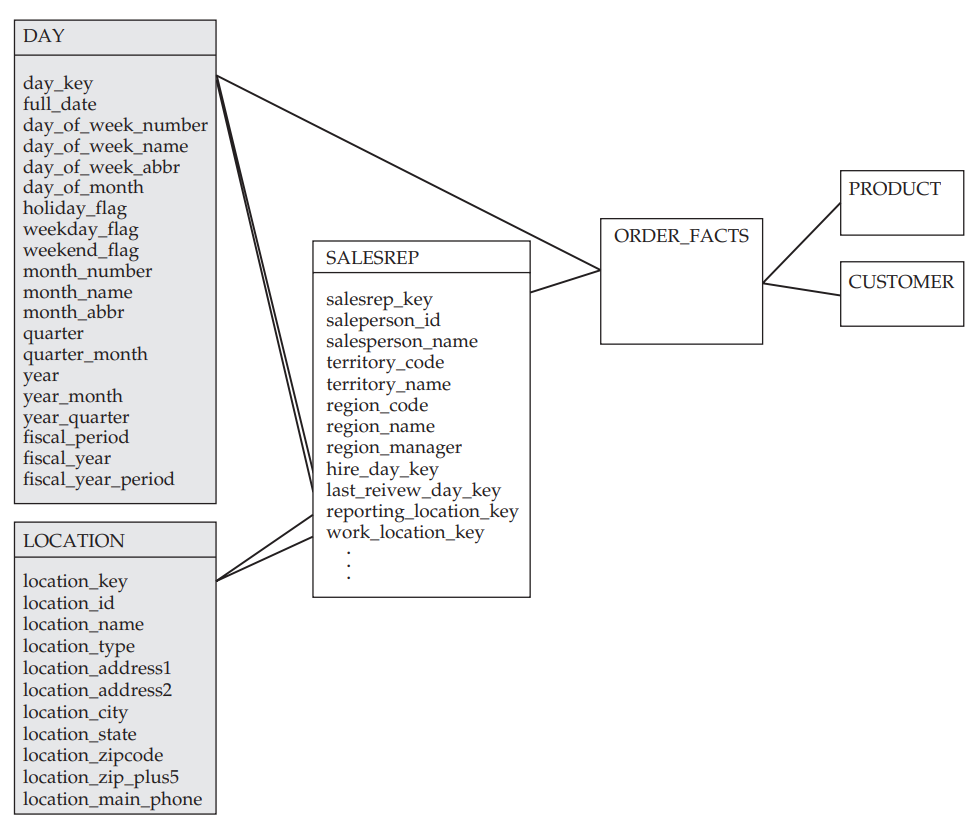
Il s’agit d’être prudent sur ce type de solution, car nous appliquons ici une technique de normalisation alors que nous cherchons à adopter une approche non normalisée. La conséquence de la normalisation étant une complexification des requêtes et une diminution des performances lors de l’interrogation. Mais, dans ce contexte précis la solution est acceptable.
Lecture Dimension déportée pour gérer les dimensions volumineuses : Star Schema. Christopher Adamson. pages 163-169
Lecture Dimension déportée : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 170-171, 169, 202