Contexte
Les dimensions sont utilisées comme axe d’analyse pour explorer nos données. Une dimension peut être vue comme un catalogue qui fait l’inventaire “d’objets” : la liste des clients, des produits, des périodes d’observation. Ces catalogues de données ne sont pas immuables : les données peuvent changer. Ces changements peuvent être de nature différentes : la correction d’une erreur, un changement occasionnel sur une petite partie des données, des changements rapides ou concernant un plus grand volume de données. Dans cette section, nous allons nous intéresser aux changements peu fréquents qui sont gérés par les dimensions à évolution lente.
Il existe 3 types d’évolutions lentes possibles qui correspondent à des besoins d’historisation différents :
- Évolution de type 1 - Écrasement de la valeur (pas d’historisation)
- Évolution de type 2 - Sauvegarde de chaque modification
- Évolution de type 3 - Sauvegarde de la dernière modification
Prenons l’exemple d’une table de faits Order_facts dont l’objectif est de rassembler les informations concernant des commandes.
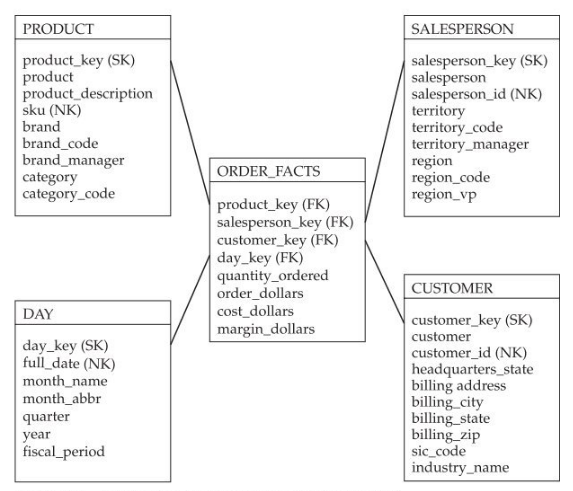
Lecture Dimension à évolution lente : Star Schema. Christopher Adamson. pages 44-46, 171
Lecture Dimension à évolution lente : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 84-93
Évolution de type 1 : Écrasement de la valeur
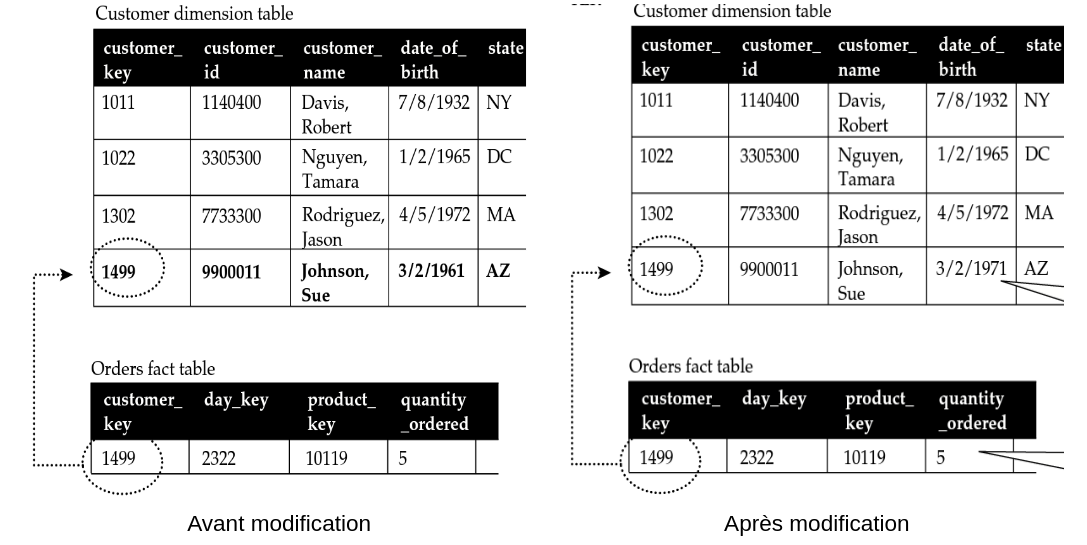
Considérons le client Johnson Sue (1499). Sa date de naissance est erronée dans le système. La date de naissance est généralement de type FV (Fixed Value) c’est-à-dire qu’elle n’est pas censée changer. Dans ce contexte, nous avons besoin de procéder à une correction de la valeur sans conservation de l’historique (voir figure ci-dessous). L’ancienne valeur est donc écrasée. On appliquera cette même approche aux attributs de type CV (Current Value) dont on n’a pas besoin de conserver l’historique.
On constate enfin que cette modification n’a aucun impact sur la table de faits. Cependant, si des agrégats avaient été précalculés (sur tous les clients d’une tranche d’âge par exemple), il est nécessaire de les reconstruire.
Lecture Évolution de type 1 (CV) : Star Schema. Christopher Adamson. pages 46-48, 171
Lecture Évolution de type 1 (CV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 84-88
Évolution de type 2 : Ajout d’une nouvelle ligne à chaque modification
Considérons toujours le même client Johnson Sue (ID 1499) qui, cette fois-ci, déménage de l’Arizona AZ à la Californie CA. Après discussion avec les experts métiers, il a été jugé important de garder l’historique complet des changements d’adresse des clients lorsqu’ils changent d’état. En effet, certaines requêtes sont spécifiques aux performances des magasins selon les différentes zones géographiques. Il est ainsi nécessaire, pour une période donnée, d’identifier tous les clients qui habitaient dans un état donné.
L’attribut state est donc de type HV (Historic Value). Pour gérer les changements de cet attribut, nous allons créer une nouvelle ligne dans la dimension :
- Avec une nouvelle valeur de clef artificielle : le client
Johnson Sueaura donc 2 clefs associées1499et2507qui correspondront chacune à une adresse différente. - Pour faire le lien entre ces 2 lignes, nous utilisons la clef métier (Business Key
BK)customer_idqui conserve sa valeur9900011.
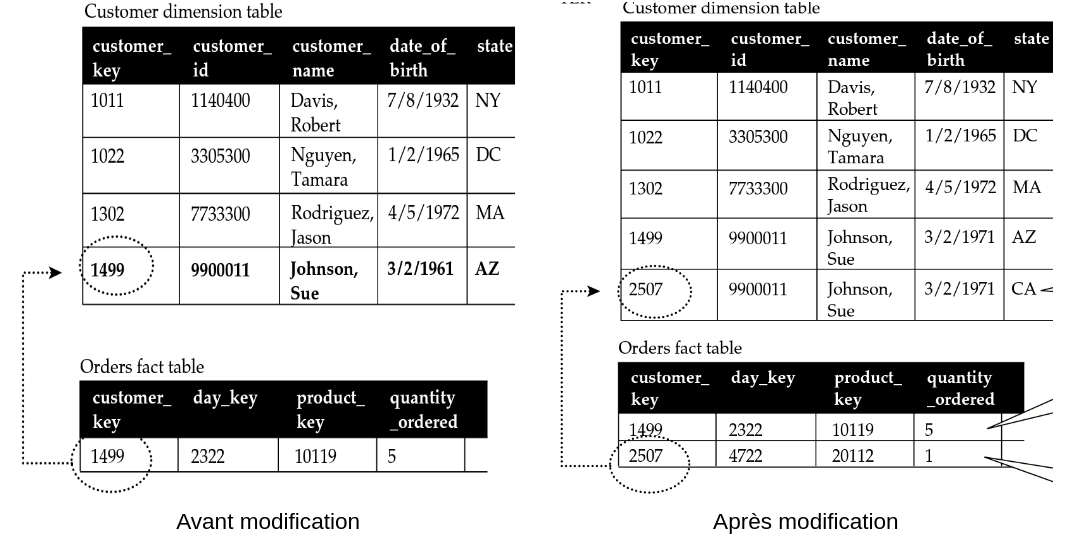
Dans ce type d’évolution, il n’est pas nécessaire de reconstruire les agrégats dans la table de faits : rien ne change pour les données passées. Par contre, désormais, toutes les commandes effectuées par le client Johnson Sue se feront avec son nouvel identifiant 2507.
Attention toutefois à ce type d’évolution. Chaque modification induit l’ajout d’une nouvelle ligne. Il est donc nécessaire de faire attention à la taille de la dimension et à sa croissance. Si la dimension devient trop grande, il faut adopter la solution concernant les grandes dimensions changeantes ou à évolution rapide (voir ci-dessous).
Enfin, c’est l’occasion de revenir sur la notion de clef artificielle. Nous avons vu précédemment qu’elles étaient utiles pour nous isoler du système opérationnel, nous nous rendons compte ici qu’elles sont indispensables pour la gestion des évolutions de type 2.
Lecture Évolution de type 2 (HV) : Star Schema. Christopher Adamson. pages 48-51
Lecture Évolution de type 2 (HV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 86-92
Évolution de type 3 : Ajout d’une colonne pour sauvegarder la dernière modification
Considérons une entreprise qui a segmenté le territoire du pays sur lequel elle opère, en 2 régions : Est et Ouest. Une croissance de l’entreprise et une restructuration ont conduit à redécouper le territoire de manière plus fine (Nord-Est, Sud-Est …).
Dans la figure ci-dessous, on se rend compte que certains clients ont désormais changé de zone d’affectation. Ce type de changement sera rare dans l’histoire de l’entreprise et les experts métiers veulent uniquement pouvoir observer l’impact de ce découpage administratif. Il leur est donc nécessaire de pouvoir faire des requêtes en fonction de l’ancien ou du nouveau découpage. L’attribut concerné, region, est donc de type PV (Previous Value), c’est-à-dire qu’on ne veut conserver que la valeur précédente.
La mise en œuvre de la solution d’évolution de type 3 consiste en la création de 2 attributs region, un pour la valeur courante region_current et l’autre pour la dernière valeur à historiser region_previous. Il faut faire attention à ne pas abuser de ce type d’évolution, car cela va faire grandir très rapidement le nombre de colonnes de la dimension.
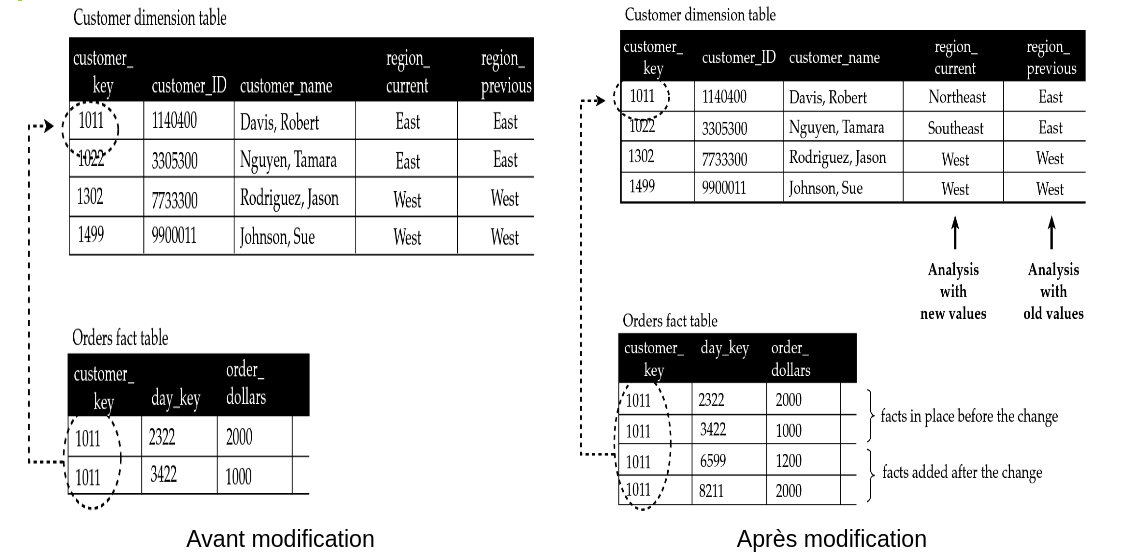
A chaque modification, la valeur courante de la région est sauvegardée dans region_previous, et la nouvelle valeur est mise dans region_current. Au niveau de la table de faits, il sera nécessaire de recalculer tous les agrégats (en fonction du point de vue actuel ou passé que l’on souhaite observer).
Lecture Évolution de type 3 (PV) : Star Schema. Christopher Adamson. pages 180-186
Lecture Évolution de type 3 (PV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 88, 188-189
Évolution hybrides
Il existe certaines situations où il est nécessaire de combiner les solutions précédentes. Nous ne les détaillerons pas ici mais si vous êtes intéressés vous pouvez utiliser les références ci-dessous.
Lecture Évolution hybrides (CV/HV) : Star Schema. Christopher Adamson. pages 186-192
Lecture Évolution hybrides (CV/HV) : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 88, 186-188