Avant de lire ce contenu, vous devez obligatoirement avoir compris la notion de schéma dimensionnel :
- Modélisation dimensionnelle - Introduction
Granularité
Diaporama Granularité
Définition
Prenons l’exemple d’une table de faits Order_facts dont l’objectif est de rassembler les informations concernants des commandes.
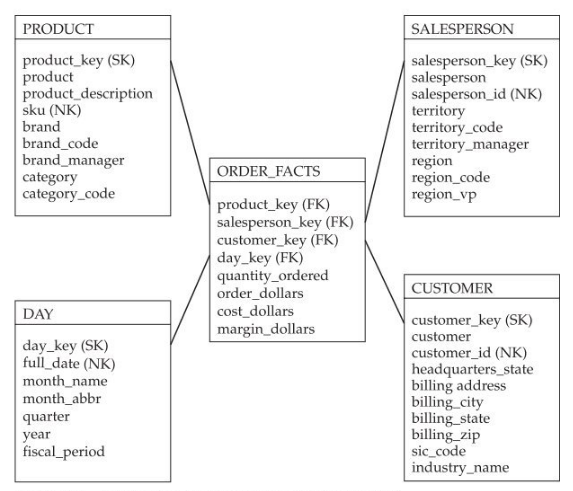
Source du schéma : Adamson, Christopher. Star Schema. Osborne/McGraw-Hill, 2010, page 30
La granularité d’une table de faits est très importante car elle permet de comprendre la nature des différents faits. De manière plus concrète la granularité définit la nature d’une ligne de la tables de faits. Sur l’exemple ci-dessus les faits Quantity Ordered, Order Dollars, Cost Dollars et Margin Dollars sont calculés par produit (PRODUCT), par vendeur (SALESPERSON), par client (CUSTOMER) et par date de vente (DAY).
- Grain / Granularité
- Le grain est ce qui permet de définir le niveau de détail des informations présentes dans une ligne d’une table de faits. Il est défini par un ensemble minimal de dimensions.
Ainsi, la granularité d’une table de faits est son niveau de détails :
- Elle définit le contexte précis des différents faits.
- Elle garantit que tous les faits sont enregistrés avec le même niveau de détail.
La granularité peut être exprimée de 2 manières différentes :
- A l’aide d’une définition dimensionnelle en énumérant les dimensions associées :
PRODUCT,SALESPERSON,CUSTOMER,DAY. - A l’aide d’une définition métier, en utilisant des termes issus du domaine métier sans référence explicite aux dimensions : Ventes de produits effectués par un vendeur à un client donné, un jour donné.
Attention, le grain correspond à un sous-ensemble de l’ensemble des dimensions liées à la table de faits : ce n’est pas forcément toujours l’intégralité des dimensions comme dans l’exemple ci-dessus.
Une table de faits comporte plusieurs faits. Tous ces faits doivent correspondre à un même contexte. Par exemple, pour une commande, on pourra avoir pour chacun des produits commandés : la quantité commandée et le montant total. Dans ce cas, la quantité et le montant sont relatifs à un même contexte : la commande et le produit.
Lorsque deux faits correspondent à deux grains différents, c’est qu’ils ne participent pas au même processus, et qu’ils doivent donc être stockés dans deux tables de faits différentes.
Lorsque deux faits dans deux tables de faits différentes ont la même définition, la même unité de mesure et le même mode de calcul on dit qu’il s’agit de faits conformes, même s’ils ne sont pas définis au même grain.
Lectures sur ce thème
Lecture Granularité d'une table de faits : Star Schema. Christopher Adamson. pages 42, 67-69
Lecture Granularité d'une table de faits : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 8-9, 233
Lecture Granularité d'un événement : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. page 54
Les Faits
Les différentes propriétés d’additivité des faits
Lors du choix des faits il est important de se poser la question de leur propriété d’additivité :
- Fait additif
- Un fait additif peut être additionné selon n’importe quel dimension. Par exemple, un chiffre d’affaire.
- Fait semi-additif
- Un fait semi-additif ne peut être additionné selon certaines dimensions. Par exemple, le nombre de colis restant à livrer à un instant donné n’est pas additif temporellement mais l’est spatialement.
- Fait non-additif
- Un fait non-additif ne peut jamais être additionné. La seule chose possible est d’effectuer des comptages ou des moyennes. Par exemple, le prix unitaire d’un produit.
Les faits conformes
- Faits conformes
- Un fait est dit conforme, s’il existe à différents endroits en portant le même nom et que les définitions et modes de calculs sous-jacents sont les mêmes. @Kimball2003
Les différents types de clefs
Diaporama Les différents types de clefs
Notions de base
- Clef primaire
- Une clef primaire définit de manière unique chaque ligne de la table. Chacune de ses valeurs est unique et non NULL.
- Clef étrangère
- Une clef étrangère référence un attribut d’une autre table.
- Clef composite
- Une clef composite est composée de plusieurs attributs.
- Clef candidate
- Une clef candidate est une clef ayant toutes les propriétés requises pour être une clef primaire.
- Clef alternative
- Une clef alternative est une clef candidate pouvant être utilisée à la place de la clef primaire.
| Student_ID (PK) | Firstname | Lastname | |
|---|---|---|---|
| R666 | Lex | Luthor | lex.luthor@imt-atlantique.fr |
| B613 | Olivia | Pope | olivia.pope@imt-atlantique.fr |
Une clef primaire est un ensemble d’attributs qui détermine fonctionnellement tous les autres attributs de la table.
Ici Student_ID et Email sont deux clefs candidates. On ne peut pas utiliser la combinaison de Firstname et Lastname en tant que clef composite car il y a un risque de doublon. La clef choisie pour être la clef primaire est Student_ID.
Notions avancées
- Clef naturelle
- Une clef naturelle est une clef utilisée pour définir quelque chose du monde réel.
- Clef métier
- Une clef métier est une clef primaire d’un système source.
- Clef artificielle ou clef de substitution
- Une clef artificielle est utilisée en tant que clef dimensionnelle, il s’agit d’une clef sans signification qui est auto-générée (en général une séquence de nombres) pour remplacer une clef naturelle.
| id (PK) | Firstname | Lastname | Student_ID | |
|---|---|---|---|---|
| 1 | Lex | Luthor | R666 | lex.luthor@imt-atlantique.fr |
| 2 | Olivia | Pope | B613 | olivia.pope@imt-atlantique.fr] |
Ici Student_ID est une clef métier et naturelle tandis que Email est une clef naturelle. Afin de s’isoler du monde réel et du système source, une clef artificielle id est créée afin d’avoir la garantie que la clef primaire n’évoluera pas au cours du temps.
Lectures sur ce thème
Lecture Clef naturelle, clef artificielle : Star Schema. Christopher Adamson. pages 11, 30
Lecture Différents types de clefs : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. page 142
Dimension dégénérée
Diaporama Dimension dégénérée
Définition
Reprenons l’exemple précédent d’une table de faits Order_facts dont l’objectif est de rassembler les informations concernants des commandes. Le grain de cette table de faits est en fait une ligne de la commande : chaque ligne de la table concerne un produit (PRODUCT) commandé par un client donné (CUSTOMER) à un commercial donné (SALESPERSON) à une date donnée (DAY). La commande globale réunissant l’ensemble des produits commandés par le client (une entreprise) éventuellement auprès de différents commerciaux.
Source du schéma : Adamson, Christopher. Star Schema. Osborne/McGraw-Hill, 2010, page 30
Que faire si nous désirions ajouter des attributs dimensionnels qui ne concernent aucune des tables de dimension identifiées, par exemple un numéro de commande order_id ou un numéro de ligne de commande (pour un produit donné) order_line_id ?
La solution (voir image ci-dessous) est d’utiliser une dimension dégénérée, c’est à dire une dimension que l’on stocke dans la table de faits sous la forme d’un unique attribut. Il s’agit d’un attribut qui peut servir d’axe d’analyse sans table de dimension. Parfois, il définit également le grain de la table de faits.

Lectures sur ce thème
Lecture Dimension dégénéré : Star Schema. Christopher Adamson. pages 43, 57, 96
Lecture Dimension dégénéré : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 62, 94
Dimensions conformes
Diaporama Dimensions conformes
Définition
La notion de dimension conforme est une solution pour permettre de faire des analyses qui concernent plusieurs processus métiers de l’entreprise tout en conservant la cohérence des données.
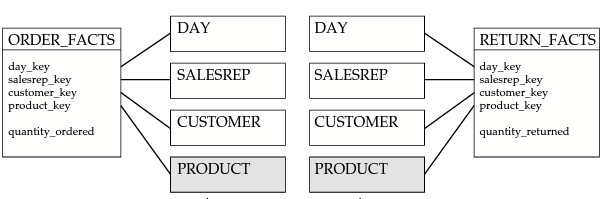
Source du schéma : Corr, Laurence, and Jim Stagnitto. Agile Data Warehouse Design: Collaborative Dimensional Modeling
Intéressons-nous, par exemple, aux requêtes suivantes :
- Par mois et par produit, nombre de commandes et de retours
- Par mois, liste des produits dont le nombre de retours est supérieur à 2
Si notre dimension PRODUCT contient des listes de produits nommés différemment, il sera impossible de consolider les commandes avec les retours.
Ainsi, pour faire des analyses sur des données provenant de différents processus (par exemple pour comparer des commandes et les retours sur livraisons ou comparer des commandes et les expéditions associées), il faut pouvoir faire des requêtes sur deux tables de faits différentes (la table des commandes et la table des retours ou la table des commandes et la tables des expéditions).
Ces tables de faits ne sont jamais directement reliées entre-elles. Lorsque des tables de faits sont reliées, elles le sont par l’intermédiaire de dimensions communes dites dimensions conformes.
Si les produits, dans la gestion des commandes, n’ont pas les mêmes caractéristiques que les produits dans la gestion des expéditions, il ne sera pas possible de faire des requêtes portant sur les produits commandés et expédiés.
- Dimensions conformes
- Considérons un ensemble de dimensions. Ces dimensions sont dites conformes s’il existe une dimension D de l’ensemble telle que pour toutes les autres :
- l’ensemble de leurs attributs est un sous-ensemble des attributs de D (même nom, même type, mêmes valeurs),
- l’ensemble de leurs lignes est un sous-ensemble des lignes de D.
- Obtenir des analyses cohérentes entre elles.
- Pouvoir faire de l’analyse multi processus (jointures entre tables de faits).
Les dimensions conformes sont donc la pierre angulaire du bus de l’entrepôt de données.
Lectures sur ce thème
Lecture Dimensions conformes : Star Schema. Christopher Adamson. pages 85-97
Lecture Dimensions conformes : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 97-99, 128
Lecture Dimensions synthétiques : Star Schema. Christopher Adamson. pages 95-96
Lecture Dimensions synthétiques : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 98, 128
Lecture Dimensions échangeables : Star Schema. Christopher Adamson. pages 310-312
Lecture Dimensions échangeables : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 98, 128
Lecture Dimensions de rôles : Star Schema. Christopher Adamson. pages 128-131
Lecture Dimensions de rôles : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto. pages 98, 108-111, 128
Architecture en bus
Diaporama Architecture en bus
Définition
Le “bus” en informatique
En informatique, un bus est un mécanisme permettant de transmettre/partager des informations entre plusieurs composants.
Pourquoi une architecture en bus dans le domaine de la Business Intelligence ?
La modélisation dimensionnelle est une activité de planification stratégique dans le sens où elle permet de modéliser les besoins des différentes parties prenantes tout en préservant la cohérence des données entre les différents datamarts.

Source du schéma : Kimball, Ralph, and Ross, Margy. The Data Warehouse Tooolkit: The Complete Guide to Dimensional Modeling.
Matrice de bus

Source du schéma : Agile Data Warehouse Design: Collaborative Dimensional Modeling. Laurence Corr and Jim Stagnitto.
La matrice de bus est un moyen de représenter de manière globale toutes les données du système d’information décisionnel. C’est un document indispensable pour permettre d’établir un dialogue clair à propos des données avec un interlocuteur.
Chaque ligne de la matrice représente un processus de l’organisation qui est associé à un marché d’information (datamart en anglais). En fait le marché d’information est tout simplement une table de faits entourées de ses dimensions.
C’est pourquoi chacune des colonnes de la matrice de bus représente les différentes dimensions présentes dans le système. Lorsqu’une dimension est utilisée par plusieurs tables de faits, elle est dite conforme.
Architecture en bus

Source du schéma : Agile Data Warehouse Design: Collaborative Dimensional Modeling. Laurence Corr and Jim Stagnitto.
Ce schéma représente le flux de transformation de données dans une architecture en bus. Chaque source de données (event source), subit une extraction, une transformation dans la zone ETL (interdite d’accès aux utilisateurs car les données ne sont pas encore mise en cohérence) pour être finalement chargée dans l’entrepôt de données qui historise et consolide les données en les mettant en cohérence notamment au moyen des dimensions conformes.
Nous voyons ici qu’un datamart n’est pas dédié à un service de l’organisation mais répond à un besoin global qui peut être partagé et interprété de la même manière par différentes parties prenantes de l’organisation.
Lectures sur ce thème
Lecture Architecture en bus : Star Schema. Christopher Adamson. pages 100-104
Lecture Architecture en bus : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto.pages 100-101, 128
Lecture Matrice de bus : Star Schema. Christopher Adamson. pages 100-101
Lecture Matrice de bus : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto.pages 101-102, 128
Lecture Matrice d'événements : Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema Laurence Corr, and Jim Stagnitto.pages 102-103